先日、もはや冬の風物詩となっている”M-1グランプリ”が開催され、見事に霜降り明星が優勝を飾りました。今回はM-1史上最年少の優勝かつ、平成生まれ芸人の初優勝ということで、平成最後の大会で様々な記録が生まれました。
そんな中、大会以上に大きな話題になっているのが、M-1審査員への暴言批判騒動。
事の発端となったのは、今回7位で敗退した「スーパーマラドーナ」武智が『M-1グランプリ』放送後に配信したインスタライブ。
動画に映った2017年チャンピオン・久保田は泥酔した様子で、「酔ってるからっていうのを理由に言いますけど、そろそろもうやめてください」と発言。
さらに、「自分目線の、自分の感情だけで審査せんといてください。1点で人の一生変わるんで。理解してください」と批判。
具体的な審査員の名前は口にしなかったものの、久保田らは「オバハン」と連呼。「たぶん、お笑いマニアの人は分かってますわ。お前だよ、一番、お前だよ。分かんだろ、右側の!」と、久保田はカメラに向かって威嚇していた。
今回、一番右の審査席に座っていたのは上沼。また、審査員の中で女性は上沼しかいなかったことから、「オバハン」は上沼のことだと推測される。
※リアルライブより
もはやM-1グランプリよりも大きな話題になっていますよね。
僕が気になったのは、
「自分目線の、自分の感情だけで審査せんといてください。1点で人の一生変わるんで。理解してください」
という発言。そこで、本当に審査員が自分の感情(好き嫌い)で審査をしていたのか、今回のM-1を例に検証してみることにしました。
審査員の得点一覧を見てみよう
なにはともあれ、まずはM-1グランプリ2018決勝の得点一覧(最終決戦は除く)を見ていきましょう。
下の表中の数値は得点を示しています。行が出場者で、列が審査員で、出場者の表示順は左から出番順になっています。
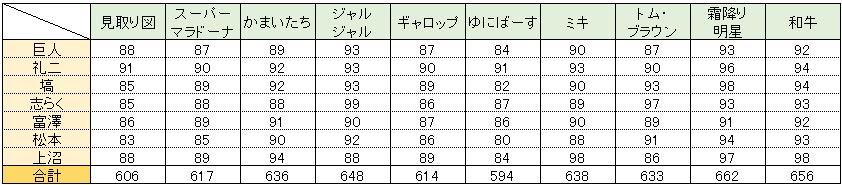
パッと見の感想にはなりますが、
みな、得点が高い!
『好き嫌い。。。』と言いつつ、最低点が80点って。。。
まあ、それだけ実力者が揃っているということなんでしょう。
さっそく検証を進めてみた
今回、とろサーモン久保田の「自分の感情だけで審査せんといてください」という発言をもとに、”審査員が本当に好き嫌いで審査しているか”検証していこうかと思いますが、まずは”好き嫌い”の定義を決めます。
ここでは、
好き嫌い=好きな芸人や嫌いな芸人には必要以上に加点減点する
という、仮定のもと話を進めていきます。つまり、点数のばらつきが大きい審査員ほど好き嫌いで判定しているということにしていきます。
検証に用いる方法
検証に用いる方法と言っても、ばらつきを見ていくだけなので簡単に。
”分散”と”標準偏差”で見ていきたいと思います。分散と標準偏差を簡単に説明すると以下の通り。
- 偏差=各データの平均との差
- 分散=偏差の2乗の合計
- 標準偏差=分散の平方根
分散も標準偏差も概念は同じで、標準偏差には単位がつけられるというのが特徴です。この場合、標準偏差の単位は”点”です。
なお、今回根拠とした図については、データの母数が少なかったため、きちんとしたグラフが作成できるように調整しているため、厳密な統計的には若干の誤差があると思いますがご了承ください。
まずは出場者ごとの検証
まずは、出場者ごとの検証です。
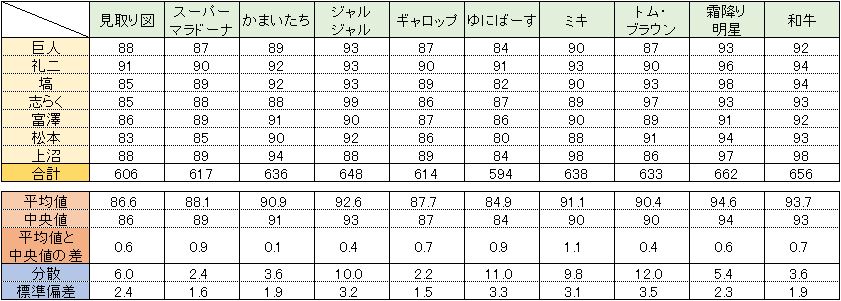
分散や標準偏差の値の大きなコンビほど、”審査員の好き嫌いの評価が分かれたコンビ”ということになります。
この場合だと、『ジャルジャル』『ゆにばーす』『トム・ブラウン』は、”審査員の評価が分かれた”という風にとらえることができるでしょう。
逆に、今回問題発言が話題にになっている『スーパーマラドーナ』や、『かまいたち』『ギャロップ』『和牛』に関しては、どの審査員も似たような評価をしたということで、逆に言えば”人によって好みが分かれづらいコンビだった”と言うことができます。

箱ひげ図も作ってみたので、載せておきます。箱ひげ図の見方は、
長方形の箱の真ん中の線は「中央値」です。データを小さい順(大きい順)に並べた時に、個数で見て真ん中に位置する値で、データの集まりの「中心」を表しています。箱の両端は、データを並べた時に、個数で見てちょうど4分の1(3)に位置する値です。つまり、25%目、75%目ということになりますね。
最初と最後の「ひげ」の部分、これはデータ並べた時に、一番小さい(大きい)データを表しています。「ひげ」の部分からデータが始まり、「ひげ」の部分でデータが終わります。
つまり、箱ひげ図とは、データを順番に並べて、始まり、全体の4分の1、4分の2、4分の3、終わりに達した地点にマークをしているだけのグラフで、データの真ん中を表す中央値(4分の2)を中心に、上下にどれくらい「散らばっている」かを確認するもの。
25%〜75%の間を「四分位範囲」と呼び、この範囲が狭ければ真ん中にデータが集まっている、範囲が広ければデータが散らばっていると言えます。
この図から、分散や標準偏差が示した結果を体感的に把握することができますね。
審査員ごとの検証
さて本題。先ほどまでは出場者で見ていきましたが、審査員ごとの点数のばらつきはどうなのでしょうか。

表を見てみるとこんな感じです。こちらは割とくっきり分かれたように思います。
『塙宣之』『立川志らく』『松本人志』『上沼恵美子』は点数のつけ方にばらつきが大きく、『オール巨人』『中川礼二』『富澤たけし』はばらつきが少ないと言う結果になりました。
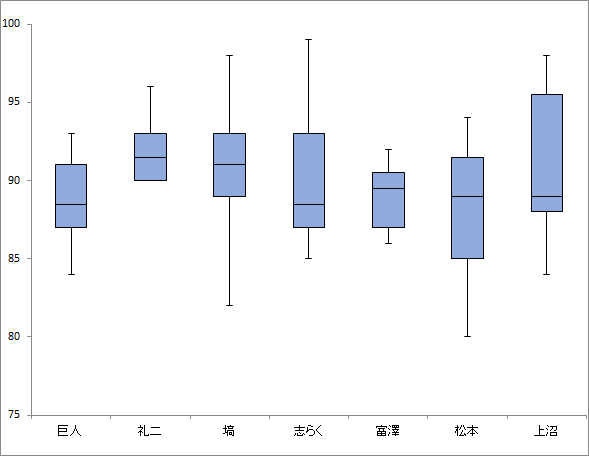
ちなみに、箱ひげ図はこんな感じ。上沼恵美子は中央の箱が大きく、点数がまんべんなく散っていて思ったより激しく好き嫌いが分かれてはいないなという印象。逆に塙宣之は、ひげの部分が長く、箱が小さいことから、大半のコンビに対しては同じくらいの点をつけ、少数のコンビに対しては極端に高い点や低い点をつけていることがわかります。
まとめ
と、いう風に今回のM-1グランプリを振り返ってみましたが、意外と点数のつけ方にクセがあるのが分かったのではないでしょうか。
これを踏まえて思うことは、コンテストにおいては審査員にある程度の好き嫌いがあってもいいんじゃないかということ。
やはりコンテストの性質上”競う”ことを目的としているため、差が開かなくては意味が無いと思うんです。仮に一点や二点の差をつけて評価したとしても、それは誤差程度の差でしかないため、ある程度極端な評価は必要だと思います。
ただし、審査員の人数が少ないと個人の好みがモロに出てしまうため、もう少し審査員の人数を増やすべきではないかと思っています。
今回、とろサーモン久保田やスーパーマラドーナ武智は『審査員の好き嫌いで評価をすること』を問題視していましたが、あえて問題提起するのであれば、好き嫌いが出やすい評価の体制を批判すべきだったのではないでしょうか。
一方で、評価される側の辛さというものも、わからなくはありません。今回は多くの批判を浴びてしまった彼らですが、今後、皆を納得させるくらいの漫才を見せられるよう頑張ってもらいたいものですね。


コメント
なんかクオリティー高くて、やばいな。
さいご、おあとがよろしいな。
ありがとう!
わざわざコメントくれてたんや!!
これからもがんばります。